Java hashCode()
In the Java programming language, every class must provide a hashCode() method which digests the data stored in an instance of the class into a single hash value (a 32-bit signed integer). This hash is used by other code when storing or manipulating the instance - the values are intended to be evenly distributed for varied inputs in order to avoid clustering. This property is important to the performance of hash tables and other data structures that store objects in groups ("buckets") based on their computed hash values.
Contents |
hashCode() in general
All the classes inherit a basic hash scheme from the fundamental base class java.lang.Object, but instead many override this to provide a hash function that better handles their specific data. Classes which provide their own implementation must override the object method public int hashCode().
The general contract for overridden implementations of this method is that they behave in a way consistent with the same object's equals() method: that a given object must consistently report the same hash value (unless it is changed so that the new version is no longer considered "equal" to the old), and that two objects which equals() says are equal must report the same hash value. There's no requirement that hash values be consistent between different Java implementations, or even between different execution runs of the same program, and while two unequal objects having different hashes is very desirable, this is not mandatory (that is, the hash function implemented need not be a perfect hash).[1]
For example, the class Employee might implement its hash function by composing the hashes of its members:
public class Employee{ int employeeId; String name; Department dept; // other methods would be in here @Override public int hashCode() { int hash = 1; hash = hash * 17 + employeeId; hash = hash * 31 + name.hashCode(); hash = hash * 13 + (dept == null ? 0 : dept.hashCode()); return hash; } }
The java.lang.String hash function
In an attempt to provide a fast implementation, early versions of the Java String class provided a hashCode() implementation that considered at most 16 characters picked from the string. For some common data this worked very poorly, delivering unacceptably clustered results and consequently slow hashtable performance.[2]
From Java 1.2, java.lang.String class implements its hashCode() using a product sum algorithm over the entire text of the string.[2] Given an instance s of the java.lang.String class, for example, would have a hash code 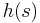 defined by
defined by
![h(s)=\sum_{i=0}^{n-1}s[i] \cdot 31^{n-1-i}](/2012-wikipedia_en_all_nopic_01_2012/I/8a6ab0ec42fd05a18d986eecc6c651b6.png)
where terms are summed using Java 32-bit int addition, ![s[i]](/2012-wikipedia_en_all_nopic_01_2012/I/90ce10bc65abeaa3715038c6647c5fbd.png) denotes the
denotes the  th character of the string, and
th character of the string, and  is the length of
is the length of s.[3][4]
As with any general hashing function, collisions are possible. For example, the strings "Ea" and "FB" have the same hash value. The hashCode() implementation of String uses the prime number 31 and the difference between 'a' and 'B' is just 31, so the calculation is 70 × 31 + 66 = 69 × 31 + 97.
Sample implementations of the java.lang.String algorithm
Java
Note: this is not the implementation of hashCode() in java.lang.String, which is overly complicated for this example; this is an example of how one might implement the algorithm as a static method.
public static int calculate_hash(String input) { int h = 0; int len = input.length(); for (int i = 0; i < len; i++) { h = 31 * h + input.charAt(i); } return h; }
References
- "Always override hashCode when you override equals" in Bloch, Joshua (2008), Effective Java (2 ed.), Addison-Wesley, ISBN 978-0-321-35668-0
- ^ java.lang.Object.hashCode() documentation, Java SE 1.5.0 documentation, Oracle Inc.
- ^ a b Bloch
- ^ java.lang.String.hashcode() documentation, Java SE 1.5.0 documentation, Oracle Inc.
- ^ Choice of hash function -> The String hash function", Data Structures course notes (2006), Peter M Williams, University of Sussex School of Informatics
External links
- "Java theory and practice: Hashing it out", Brian Goetz, IBM Developer Works article, 27 May 2003
- "How the String hash function works (and implications for other hash functions)", Neil Coffey, Javamex